Synthetic Data란 무엇인가요? 데이터 부족 시대 AI 학습을 확장하는 전략
요즘 AI 프로젝트를 진행하다 보면 이런 말을 자주 듣게 돼요.
“데이터가 부족해서 모델 성능이 안 나옵니다.”
친구, 정쌤도 현장에서 비슷한 상황을 여러 번 겪었어요.
모델 구조는 괜찮은데, 학습 데이터가 충분하지 않거나
개인정보 이슈 때문에 데이터를 마음대로 활용하지 못하는 경우가 많죠.
그래서 오늘은 Synthetic Data(합성 데이터)를
조금 더 전략적인 관점에서 정리해보려고 해요.
정보정비소에서는 단순 기술 설명이 아니라
“왜 지금 필요한가?”에 초점을 맞춰보겠습니다.
1️⃣ Synthetic Data란 무엇인가요?
ALT 텍스트: Synthetic Data 개념 이미지
캡션: 실제 데이터를 기반으로 생성된 가상 데이터 구조
Synthetic Data는
👉 실제 데이터의 통계적 특성과 패턴을 학습한 뒤
AI가 새롭게 만들어낸 인공 데이터입니다.
여기서 중요한 건 “복사본”이 아니라는 점이에요.
- 실제 데이터의 구조는 반영하지만
- 개별 개인 정보는 포함하지 않고
- 새로운 샘플을 생성한다는 것이 핵심입니다.
예를 들어 의료 데이터를 직접 사용할 수 없다면,
유사한 특성을 가진 가상 환자 데이터를 만들어
모델 학습에 활용할 수 있어요.
이렇게 하면 프라이버시를 보호하면서도
모델 학습은 이어갈 수 있습니다.
2️⃣ 왜 지금 Synthetic Data가 더 주목받을까요?
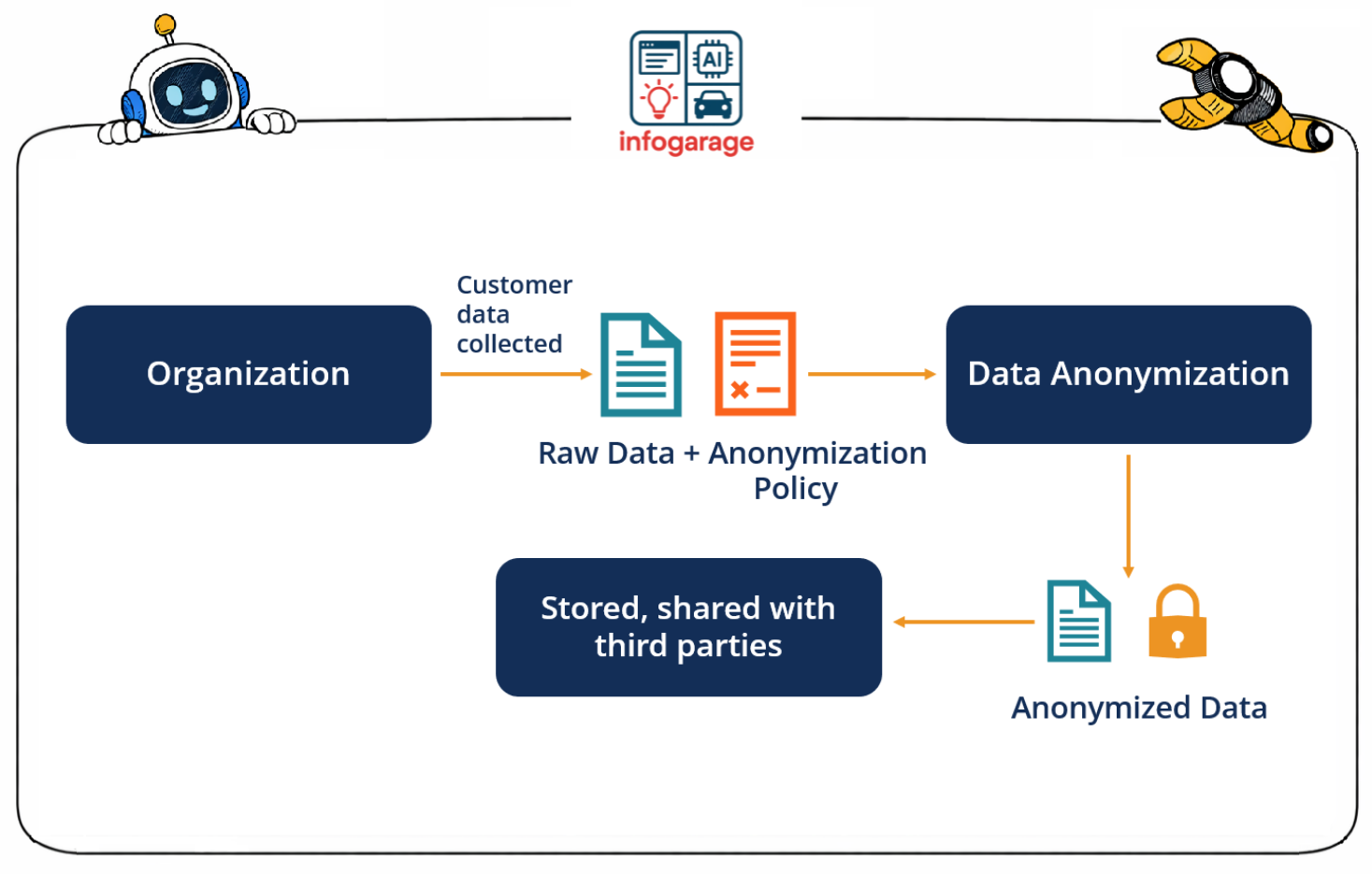
ALT 텍스트: Synthetic Data 필요성 이미지
캡션: 개인정보 보호와 데이터 부족 문제를 해결하는 대안
최근 AI 개발 환경은 예전과 많이 달라졌어요.
✔ 개인정보 보호 규제 강화
✔ 데이터 반출 제한
✔ 희귀 사례 데이터 부족
✔ 데이터 불균형 문제
특히 금융·의료·공공 분야는
데이터를 외부로 옮기는 것 자체가 쉽지 않죠.
Synthetic Data의 핵심 장점
구분효과
| 프라이버시 보호 | 실제 개인 정보 노출 최소화 |
| 희귀 데이터 생성 | 극단적·위험 상황 시뮬레이션 가능 |
| 데이터 불균형 보완 | 소수 클래스 확장 가능 |
| 테스트 환경 구축 | 보안 위험 없이 실험 가능 |
정보정비소 관점에서 보면
Synthetic Data는 단순 기술이 아니라
👉 데이터 전략의 확장 수단입니다.
3️⃣ Synthetic Data는 어떻게 만들어질까요?

ALT 텍스트: Synthetic Data 생성 과정 이미지
캡션: 생성형 모델 기반 합성 데이터 생성 흐름
Synthetic Data 생성에는 생성형 AI 모델이 활용됩니다.
대표적인 기술이 바로 GAN(Generative Adversarial Network)입니다.
GAN은 두 모델이 서로 경쟁하는 구조예요.
- 생성자(Generator)는 가짜 데이터를 만들고
- 판별자(Discriminator)는 진짜인지 가짜인지 구분합니다.
이 경쟁 과정에서 점점 더 실제와 유사한 데이터가 생성됩니다.
생성 방식 요약
방식설명
| GAN | 경쟁 구조 기반 데이터 생성 |
| VAE | 확률 분포 기반 데이터 재구성 |
| LLM 기반 | 텍스트 Synthetic Data 생성 |
| 시뮬레이션 | 디지털 트윈 환경 활용 |
예를 들어,
- 자율주행 차량의 사고 상황
- 금융 사기 패턴
- 고객 상담 로그
이런 데이터를 가상으로 생성해 모델을 훈련할 수 있어요.
4️⃣ 기업 IT 환경에서의 활용 전략

ALT 텍스트: 기업 IT 활용 이미지
캡션: AI 인프라 설계와 데이터 전략 통합 구조
기업에서는 Synthetic Data를 다양한 방식으로 활용합니다.
주요 활용 영역
✔ AI 모델 테스트 데이터 생성
✔ 보안 환경 시뮬레이션
✔ 데이터 공유 대체 수단
✔ MLOps 파이프라인 자동화
✔ 개인정보 보호 대응 전략
특히 클라우드 기반 AI 인프라에서는
Synthetic Data 생성 → 모델 학습 → 검증 → 배포까지
자동화 파이프라인으로 연결하는 경우가 늘고 있어요.
하지만 여기서 중요한 건 품질 검증입니다.
Synthetic Data가 실제 데이터의 통계적 특성을 제대로 반영하지 못하면
모델이 현실과 동떨어진 결과를 낼 수 있어요.
그래서 반드시 다음 절차가 필요합니다.
검증 단계목적
| 통계 비교 | 실제 데이터와 분포 비교 |
| 성능 테스트 | 모델 정확도 검증 |
| 편향 분석 | 왜곡 여부 확인 |
| 규제 점검 | 법적 요건 충족 확인 |
정보정비소에서는 이 부분을
“데이터 거버넌스와 연결된 전략”이라고 봅니다.
5️⃣ Synthetic Data의 한계와 균형 전략
Synthetic Data는 강력한 도구지만
만능 해결책은 아닙니다.
주요 한계
요소설명
| 원본 편향 반영 | 기존 데이터의 왜곡 유지 가능 |
| 품질 문제 | 학습 부족 시 낮은 정확도 |
| 과적합 위험 | 인공 데이터에만 최적화될 가능성 |
| 현실 괴리 | 실제 상황과 차이 발생 가능 |
그래서 가장 현실적인 접근은
👉 실제 데이터 + Synthetic Data 혼합 전략입니다.
실제 데이터를 기반으로 학습하되,
부족한 영역을 Synthetic Data로 보완하는 방식이에요.
이 균형이 모델의 신뢰성과 성능을 동시에 확보하는 방법입니다.
📌 핵심 요약 정리
Synthetic Data는 이렇게 기억하면 좋아요.
✔ 실제 데이터를 직접 쓰지 않고 학습 가능
✔ 개인정보 보호에 유리
✔ 희귀·극단적 상황 데이터 생성 가능
✔ 기업 데이터 전략의 확장 도구
✔ 반드시 품질 검증이 필요
🌿 마무리하며
AI 시대의 경쟁력은 단순히 데이터를 얼마나 많이 모았느냐가 아니라
👉 데이터를 어떻게 확장하고 설계하느냐에 달려 있습니다.
정쌤은 이렇게 생각해요.
앞으로 데이터 경쟁은 “수집”이 아니라 “설계”의 싸움이 될 것이다.
Synthetic Data는 그 설계 전략의 중요한 한 축이에요.
정보정비소에서는 앞으로도
AI 인프라, 데이터 전략, 기술 방향성을 함께 정리해보겠습니다.
오늘도 읽어주셔서 감사합니다 😊
정보정비소는 오늘도 복잡한 기술을 차분히 정리합니다.
본 글은 요약본이며, 전체 흐름은 아래 포스팅에 정리되어 있습니다.⬇️
https://m.blog.naver.com/infogarage/224192233835
데이터 부족 시대 인공지능 학습을 확장하는 Synthetic Data 활용 방식
요즘 인공지능과 머신러닝 개발 환경에서는 실제 데이터 확보가 점점 어려워지고 있어요. Synthetic Data...
blog.naver.com
'정쌤의 IT이야기' 카테고리의 다른 글
| AI 인프라 내재화 전략 클라우드 대신 직접 구축하는 기업들의 선택 이유 (3) | 2026.03.10 |
|---|---|
| 천궁2와 패트리어트 미사일 차이 무엇일까? 방공 시스템 성능 비교 (2) | 2026.03.09 |
| Explainable AI(XAI)란 무엇인가요? 인공지능 의사결정을 설명하는 기술의 핵심 (2) | 2026.03.07 |
| Federated Learning 쉽게 이해하기 데이터를 모으지 않는 AI 학습 구조 (2) | 2026.03.06 |
| 전화선 모뎀에서 생성형 AI까지 인터넷은 어떻게 진화했을까? (2) | 2026.03.05 |



